
With the multitude of academic reports published daily, ever-increasing reference formats and styles, it has become cumbersome for academics and researchers to create references and read all relevant publications. To alleviate these problems, the “Antibody & Product Development Lab (APD) Reference App” was created for easy reference search, and citation in different formats by using Optical Character Recognition (OCR) to capture the Digital Object Identifier (DOI) or title of a publication. Following this, users can easily retrieve, browse, and read translated summaries of the articles of interest. Incorporating Natural Language Processing (NLP), the app is available on both Google and Apple app stores with trials available for paid features.
There is a plethora of desktop/web-based applications to aid in report writing, particularly in the areas of referencing or generating a bibliography. Examples of this include software like the “Reference” feature in Microsoft Word®, EndNote X9 (Group, 2019), Colwiz (PLC, 2019), RefWorks (LLC, 2019), and many others. Many of these programs have limitations, requiring the first-time manual entry of publications fields such as author name, year, and other details. This manual process can be time-consuming and cumbersome to do when dealing with numerous references. Similarly, many of these programs have compatibility restrictions to specific operating software and devices. Leveraging on the mobility and increased power of smartphones/phablets, which had not only shown promise in making research easier for biomedical (Gan & Poon, The world of biomedical apps: their uses, limitations, and potential, 2016), clinical research (Gan, Cornelius, Phi-Vu, & Haw, 2016), psychology research (Gan & Goh, 2016) e.g. PsychVey (Nguyen, Lim, Budianto, & Gan, 2015), and now even common work such as mobile word processing, APD Reference App was created to provide a more flexible way of generating citations on the go. To allow seamless transfer to other platforms, the app allows the generated references to be emailed. Most importantly, the app increases convenience as users only need to provide DOI/title of the article to be cite. The app also facilitates the processing of multiple references at a time for a quick summary of the associated articles.
APD Reference app integrates multiple services, APIs, and algorithms as a single research companion to ease the writing process.
The APD Reference App was developed using Android Studio version (3.5.2) for the Android application and XCode (11.2 beta 2) for the iOS application.
With the increase of online data, extracting key information becomes increasingly difficult. Understanding this challenge, APD Reference App uses NLP for text summarization and keyword extraction by employing JSoup, Apache OpenNLP, and JGraphT in Android, and Reductio in the iOS version.
To address the challenge of extracting key information, recording and transferring large chunks of text from hard copy to soft copy, OCR was incorporated using Google’s Firebase ML Kit in both app versions for text recognition.
The application utilizes cURL, a tool for transferring data to and from a server (Stenberg) for retrieving citations. HttpUrlConnection is used for the Android version while URLSession is used for the iOS version.
The APD Reference App has 6 key features.
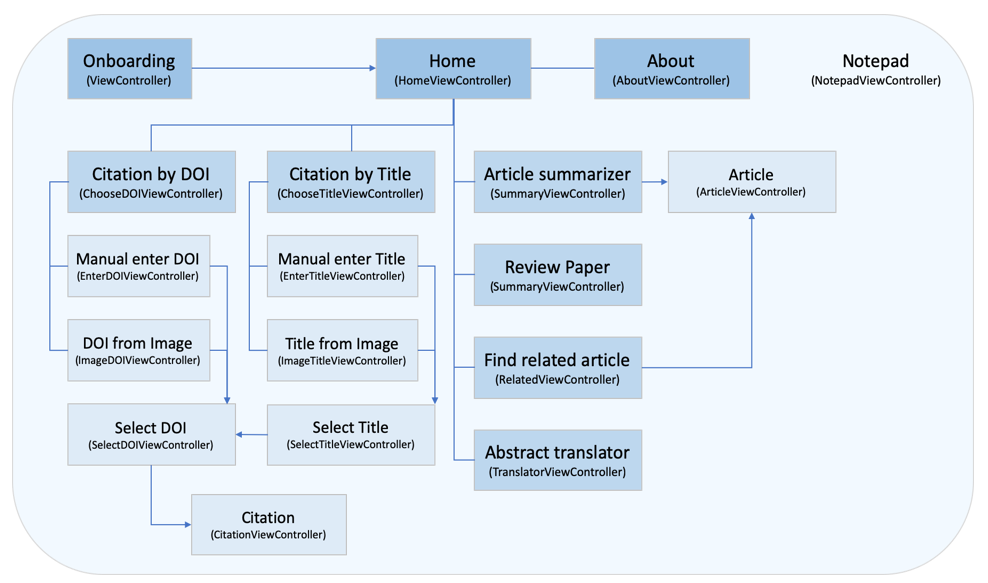
Figure 1: Structure of application
Get citations
APD Reference App is an Android and iOS mobile application that can generate citations by two parameters: DOI or title.
Approach 1: By DOI(s)

Figure 2: Uploading methods
Within this approach of DOI, there are two main methods (Figure 2) of capturing the DOI: 1) manually entering the DOI number, or 2) using OCR to capture the text from an image in the image gallery or directly from the camera. Multiple DOIs can be entered with separation using commas.
DOI capturing method 1:
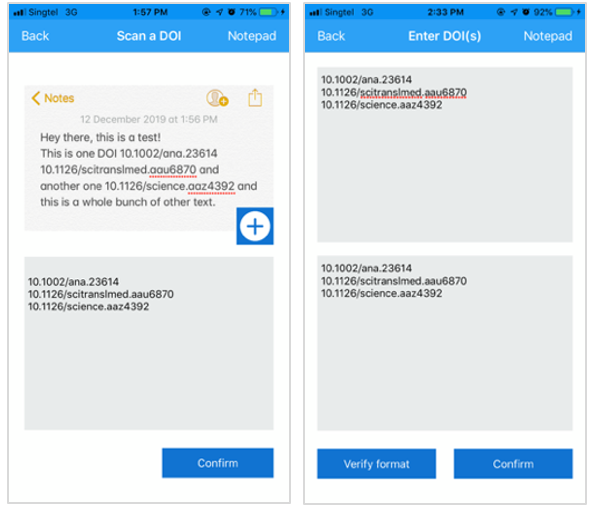
Figure 3: (Left) DOIs scanned using OCR,(Right) DOIs manually entered and validated
The capturing of the DOI/text is performed based on the Firebase ML OCR technology and is operable in the presence of other text (Figure 3 left panel). Multiple DOIs can be captured if they are present on the image with the use of regular expression (JustGreatSoftwareCo.Ltd., 2019).
DOI capturing method 2:
When the DOI is manually entered, the text will pass through the regular expression checks for validation (Figure 3 right panel).
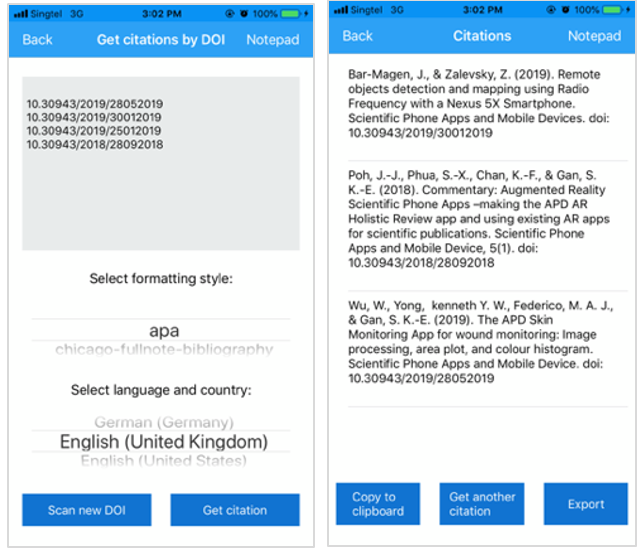
Figure 4: (Left) Captured DOI. (Right) Generated citations.
Captured DOIs would be requested via APIs (e.g. Crossref Citation Formatting Service REST API) to retrieve the reference, referencing style, and locale that the user has selected (Figure 4 left panel). Retrieved citations will then be displayed to which the user can to copy the text to the clipboard or export for email (Figure 4 right panel).
Approach 2: By title
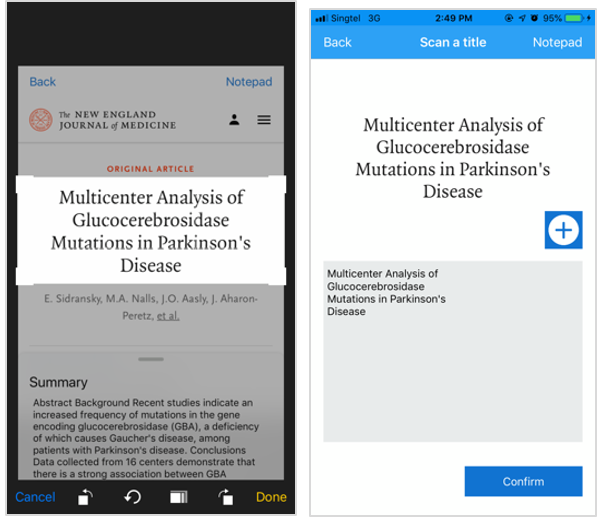
Figure 5: (Left) Cropping of title, (Right) Captured title via OCR
Citations can also be generated from the title of the article by manual entry or OCR. Although both methods utilize DOI, the use of title search is more intuitive for users.
As with DOI, OCR is used to extract the title text from the image. As all text would be captured, users would need to crop to the title only. (Figure 5 right panel).
Once the title is captured (Figure 5 right panel) and confirmed by user input, the top five articles matching the title would be retrieved by the API. The user can select from these top five matches, mitigating the problem concerning publications with similar titles (Figure 6 left panel). The citation of the selected article will then be retrieved via the ‘Get citations by DOI’ page for selection of formatting style (Figure 6 right panel).
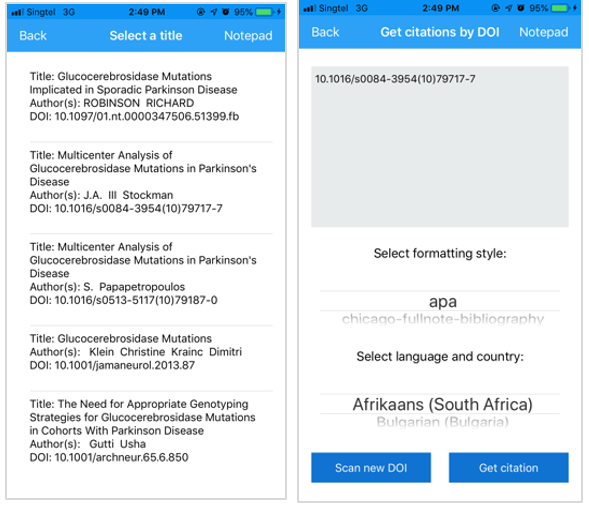
Figure 6: (Left) Top 5 articles from the title. (Right) DOI of the selected article.
Article summarizer
The app is also able to summarize the research articles and extract keywords from the web page of the article.
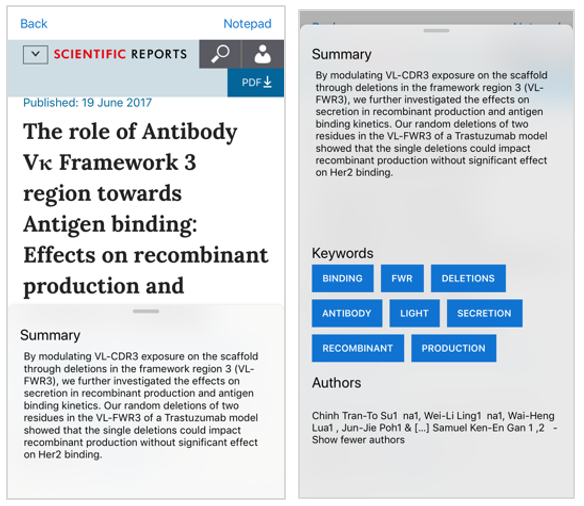
Figure 7: (Left) Article summarizer in web view, (Right) Article summarizer with keywords
In the Android version, the ‘Article Summarizer’ feature uses JSoup, Apache OpenNLP, and JGraphT. When an URL is entered and displayed, JSoup, an HTML parsing library (Baeldung, 2019), extracts specific document elements from the page (Figure 7 left panel) through the TextRank (Mihalcea & Tarau, 2004) NLP algorithm. TextRank is a graph-based algorithm derived from the PageRank algorithm, and was originally used to determine the order of pages in Google searches (Brin & Page, 1998). Considering the varying nature of websites, a series of carefully ordered “if-statements” was implemented to extract the desired article text.
The sequencing of the if-statements is determined by a list of elements such as the id/class of the required document element on the web page. The program runs through each if-statement until the function finds a document element that matches the defined element and conditions in the if-statement. For instance, when extracting the article text, a website can have a document element with a class name of “article”, but the text is not found in that element but in an element with a more complex id called “article-section__content-main”. Because of instances like these, the least likely id/class need to be placed first in the function so that the correct text from that document element will be taken. As there is a multitude of websites, the if-statements were derived by trying and testing with 30 journal and article websites.
Once the article text has been retrieved, OpenNLP was leveraged upon for a simple sentence separation and text tokenization for splitting the text into sentences. Each sentence will be compared to the next and a graph will be plotted (JGraphT) for a similarity score that would be used to rank the sentences from the most similar to the least. From this array list of ranked (ordered) sentences, the 2 most relevant sentences will be shown to the user as the summary.
Similarly for keywords, the sentences will be split into individual words and common words like 'a', 'the', etc., will be removed with a “stopwords.txt” file. The top eight words will be shown to the user as the extracted keywords.
With the article summarizer feature, the app can retrieve summaries and extract keywords from websites that host multiple journals. Some examples of keywords and summaries that have been generated are shown:


Figure 8: (Top left) 10.1002/ana.23614,(Top right) 10.1016/j.cell.2008.06.037, (Bottom left) 10.1038/ni811, (Bottom right) 10.1093/brain/awt367
There are different implementation in Android and iOS versions of the app. ‘Reductio’, which runs on the same TextRank algorithm, was used for the iOS version. While the Android version uses JSoup. The iOS version uses SwiftSoup as a parsing library.

Figure 9: History
In both versions, the article summarizer feature encompasses a cache of browsed history (Figure 9). To revisit the article, the user can simply tap on the row with the title. This allows the app to be used even without internet connectivity. The cache is limited to the last 30 visited sites on the Android version. Nonetheless, both versions allow the user to clear the cache with the “delete” or “clear history” button. The Android version uses shared preferences while the iOS version uses UserDefaults and Core Data.
Finding related articles

Figure 10: Find related articles
Through the DOI, related articles can be retrieved for browsing for the user to browse.
Review paper

Figure 11: Review paper feature
The “review paper writer” feature applies a similar technology to the summary and keyword extraction feature. When multiple DOIs are enterd, the app will generate a summary from each of the research article websites, combining them to a combined review, allowing a quick summary of multiple articles at the same time.
Abstract translator
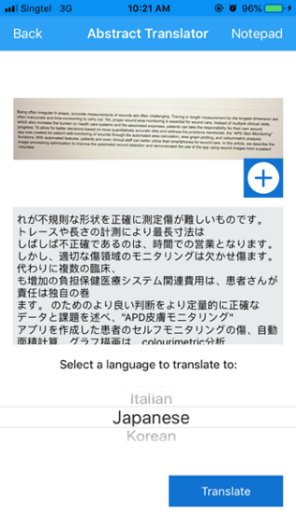
Figure 12: Translator
The last feature is the abstract translator which translates a text to and from 16 different languages (Figure 12). Input from the images is taken via the OCR.
For both iOS and Android versions, the Yandex translation API was used for this feature.
Notepad
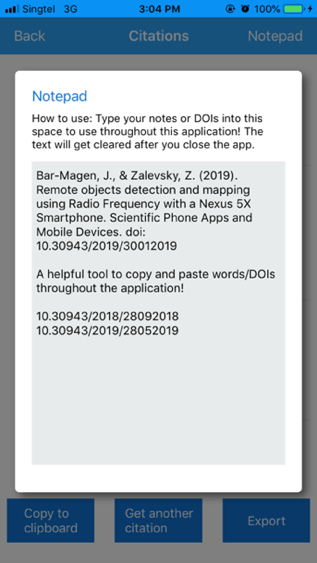
Figure 13: Notepad
Notepad is a convenient tool within the app that allows the user to copy, paste, and type notes. This will come in handy if a user wants to use the same DOIs for multiple features within the app. The user can access the notepad from the navigation bar.
The Android version uses shared preferences while the iOS version uses ‘UserDefaults’ and ‘Core Data’. The text view detects changes to the text and automatically updates the data.
The resulting keywords from the article summarizer were compared to the keywords available in articles from the Proceedings of the National Academy of Sciences of the United States of America (PNAS, 2020) shown in Figure 14.
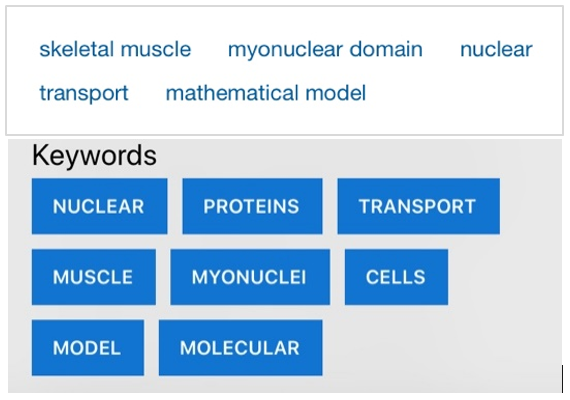
Figure 14: (Top) PNAS keywords, (Bottom) APD Reference App keywords
The example in Figure 14 was performed with an article on biological sciences. The next example shown in Figure 15, was performed with an article on psychological and cognitive sciences.
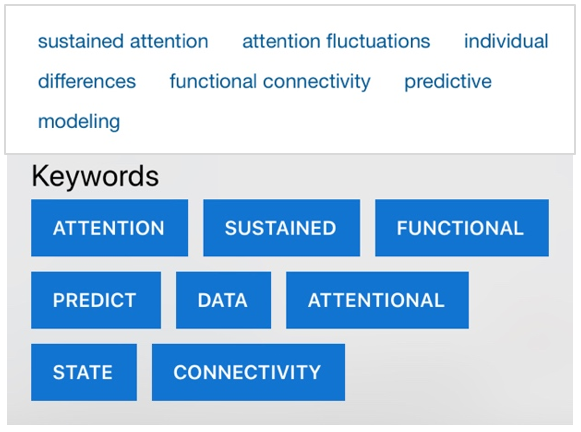
Figure 15: (Top) PNAS keywords, (Bottom) APD Reference App keywords
With the similarity in extracted words, the app demonstrates reasonable accuracy and usability.
While some journal websites, like PNAS, has incorporated keywords and a summary on the article web page, it should be noted that not all websites provide such information, thus having a use for the article summarizer feature.
Citations created through Microsoft Word “Reference” feature (Figure 16 top panel) and the APD Reference App (Figure 16 bottom panel) were also compared. The results showed that both programs generated the identical outputs (Figure 16).

Figure 16: (Top) Microsoft Word citation, (Bottom) APD Reference App citation
User Satisfaction
Both the Android and iOS versions of the app have been tested by a group of users with generally positive feedback on usefulness, particularly in easing he process of generating citation references using the smartphone and summarizing articles. The translation feature coupled with the OCR capabilities was also mentioned as a convenient tool to reduce language barriers in articles of a different language.
Currently, the OCR detects only Latin-based words, and is unable to detect other languages such as Chinese, Korean, or Japanese. Nonetheless, the text can be typed in the translation feature and auto-detected.
Unlike DOI, the title of a text cannot be automatically extracted. To work around this issue, the cropping feature was added so that the user has control over which text in the image is to be captured, but also adding an additional step.
The keyword extraction feature in the article summarizer is currently only able to extract single words. This means that phrases will be tokenized or split into separate words. This is a limitation of the algorithm since it requires words to be split in order to select the top 8 keywords to be shown. However, the words in the phrases can still be mined among the keywords in the article summarizer as shown in Figures 14 and 15.
The APD Reference App contains multiple features that make obtaining references easy by capturing text from printed materials and/or screenshots or by manually keying in a DOI or title. With the horde of features, the app is a useful companion for report preparation.
APD Reference App is available on both Google and Apple app stores. Free trials for paid features: Article summarizer, Review paper, and Find related articles, are available.
To avoid conflict of interest, the article was handled by an independent member of the editorial board. The article-processing-charge for this article was also waived.
NBO & WWL drafted the manuscript and made the iOS and Android apps. SKEG conceived the idea and supervised all aspects of the manuscript.
Anon., 2020. PNAS. [Online] Available at: https://www.pnas.org/
Baeldung. (2019, 08 16). Baeldung. Retrieved 12 20, 2019, from https://www.baeldung.com/java-with-jsoup
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual Web search engine. Computer Networks and ISDN Systems, 107-117. Retrieved from Science.
Gan, S. K.-E., Cornelius, K., Phi-Vu, N. & Haw, Y.-X., 2016. An overview of clinically and healthcare related apps in Google and Apple app stores: connecting patients, drugs, and clinicians. Scientific Phone Apps and Mobile Devices, 19 July, 2(8). DOI:https://doi.org/10.1186/s41070-016-0012-7.
Gan, S. K.-E. & Goh, B. Y.-L., 2016. Editorial: A dearth of apps for psychology: the mind, the phone, and the battery. Scientific Phone Apps and Mobile Devices, 02 April, 1(2). DOI:https://doi.org/10.1186/s41070-016-0005-6.
Gan, S. K.-E. & Poon, J.-K., 2016. The world of biomedical apps: their uses, limitations, and potential. Scientific Phone Apps and Mobilw Devices, 2(6). DOI:https://doi.org/10.1186/s41070-016-0009-2.
Group, W. o. (2019). Web of Science Group | EndNote. Retrieved 12 20, 2019, from https://endnote.com/product-details/compatibility/
JustGreatSoftwareCo.Ltd. (2019). RegexxBuddy. Retrieved 23 20, 2019, from https://www.regexbuddy.com/regex.html
LLC, P. (2019). RefWorks. Retrieved 12 23, 2019, from https://www.refworks.com/refworks2/
Mihalcea, R., & Tarau, P. (2004, July). TextRank: Bringing Order into Text. Retrieved from ACL Anthology: https://www.aclweb.org/anthology/W04-3252/
Nguyen, P.-V., Lim, J. P.-H., Budianto, I.-H. & Gan, S. K.-E., 2015. PsychVeyApp: Research survey app. Scientific Phone Apps and Mobile Devices, 1(3). DOI:https://doi.org/10.1186/s41070-015-0002-1.
PLC, I. (2019). wizdom.ai. Retrieved 12 23, 2019, from https://www.wizdom.ai/
PNAS. (2020). Retrieved from PNAS: https://www.pnas.org/
Stenberg, D. (n.d.). MIT. Retrieved 12 17, 2019

APD SKEG Pte Ltd is the member of

Scientific Phone Apps and Mobile Devices is in the Research collection of

Scientific Phone Apps and Mobile Devices is affiliated with